


Optical character recognition, more popularly known as OCR, has been a lifesaver for those who have a lot of documents, books, research materials, papers, to scan and digitize. Even though we live in an increasingly digital world, a lot of materials are still on paper, and need to be transferred by scanning. But OCR allows those scanned materials to become textual content, and therefore searchable. Google Drive has had OCR capabilities for some time now, but the latest update brings it to even more languages, rather than just English.
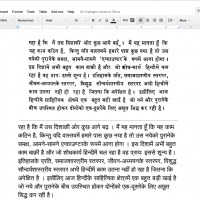
It’s pretty easy to use OCR through Google Drive, and the same steps apply to this new update. Upload a scanned document on your drive. It can be a JPEG, PNG or a PDF. Once it has finished uploading, right click on the document while you’re still on the Drive interface and then open it with Google Docs. It will then automatically open with the image or PDF, followed by the text that was extracted. The system already automatically detects what language it is in, and the extracted text will reflect that as well.
But if you want to be able to control and tell it what language it is in, you can also use the Google Drive API. If you’ve used OCR before, you know that it’s not the most accurate when it comes to extracting text, so make sure you review and edit it first before using or sending it to someone.
You’ll be able to use this new OCR capability in both the desktop version and the Drive for Android as well. If you want to know more about the technical aspect of it, you can click on the source link and read how they were able to do it not just for English, but for the huge non-English speaking market out there.
SOURCE: Google







